
The topic of Why Chunking Is the Biggest Mistake in RAG Systems is currently the subject of lively debate — readers and analysts are keeping a close eye on developments.
This is taking place in a dynamic environment: companies’ decisions and competitors’ reactions can quickly change the picture.
Retrieval-Augmented Generation (RAG) has become the default architecture for building AI-powered document intelligence systems. Most implementations follow the same pattern:
This pipeline works reasonably well for simple text. However, when applied to structured documents like clinical records, chunking can introduce serious problems.
Healthcare documents are rich with context and hierarchy. Breaking them into arbitrary chunks often leads to context loss, retrieval errors, and fragmented reasoning.
In this article, you will understand why chunking fails using a realistic clinical document example, and how structure-aware indexing and summarization can produce far better results.
Note – This post focuses on the Healthcare Domain with the patient clinical document as an example.
At first glance, this document appears small, but clinical records in real systems often span hundreds of pages across multiple visits.
These require information from multiple chunks, which chunk-based retrieval often fails to assemble.
• What treatment improved the patient’s PHQ-9 score?
• What medication is being used to treat the patient’s depression?
• What treatment approach was used along with medication?
• What interventions helped reduce the patient’s depression score?
But it does not contain medication information, so the answer becomes incomplete.
• What condition is the patient being treated for with Sertraline?
• Why was the patient referred to a psychiatrist?
• What symptoms led to the treatment plan?
Chunk C contains medication, but diagnosis is in Chunk A, so the model may not connect them.
• Did the therapy sessions improve the patient’s condition?
• What evidence shows the patient improved during treatment?
• How effective was the treatment plan?
• Why does the patient need psychiatric follow-up?
• What follow-up care is recommended after treatment?
• What ongoing care is suggested for this patient?
Chunk C contains the follow-up plan but not the context of the diagnosis or therapy outcome.
• Summarize the patient’s diagnosis, treatment, and follow-up plan.
• What treatments has the patient received for depression?
• What is the overall care plan for this patient?
• What therapy is the patient receiving?
• What treatment is the patient undergoing?
• How is the patient being treated?
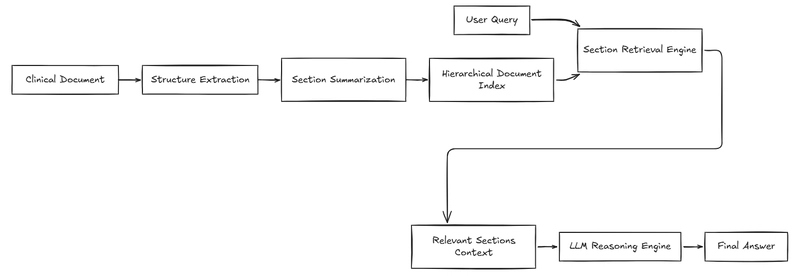
Instead of splitting documents arbitrarily, the document structure can be preserved by producing a tree based hierarchical structure.
The patient is currently prescribed Sertraline 50mg daily, with no reported side effects.
As AI becomes more integrated into healthcare systems, document understanding will play a critical role.
• Hierarchical document indexing
• Section-level summarization
• Reasoning-based retrieval
• Agentic document exploration
These approaches allow AI systems to navigate clinical documents more like human experts.
The chunking assumes documents are bags of paragraphs. But documents are actually structured knowledge systems. Even when documents appear unstructured, the structure can be inferred. And once structure exists, retrieval becomes far more accurate.
Structured documents like clinical records, it often causes more problems than it solves.
If you need the AI systems to truly understand documents, in such cases preserving the structure and allow models to reason over meaningful sections is really crucial.
Moving beyond chunking is a critical step toward building safer, more reliable document intelligence systems.
In the next blog posts, you will be walked with a realistic example on how to deal with the unstructured data and its retrieval.
Clinical document sample was referenced from https://www.supanote.ai/templates/clinical-summary-template
This blog-post contents were formatted with ChatGPT to make it more professional and produce a polished content for the targeted audience.
Are you sure you want to hide this comment? It will become hidden in your post, but will still be visible via the comment’s permalink.
For further actions, you may consider blocking this person and/or reporting abuse
DEV Community — A space to discuss and keep up software development and manage your software career
Built on Forem — the open source software that powers DEV and other inclusive communities.
Why it matters
News like this often changes audience expectations and competitors’ plans.
When one player makes a move, others usually react — it is worth reading the event in context.
What to look out for next
The full picture will become clear in time, but the headline already shows the dynamics of the industry.
Further statements and user reactions will add to the story.