
The topic of Ace These 5 Backend Concepts to Become a Senior Engineer is currently the subject of lively debate — readers and analysts are keeping a close eye on developments.
This is taking place in a dynamic environment: companies’ decisions and competitors’ reactions can quickly change the picture.
Nowadays, AI can help ship almost every backend feature in a few minutes, but it does not replace the fundamentals you need to understand when your agent is moving in the wrong direction.
CRUD endpoints, webhooks, external integrations, file import/export, and background jobs may look simple on the surface. But in real systems, each of them hides a lot of important decisions.
From my experience, these five topics show up in almost every backend project. If you understand them deeply, you become much more valuable than someone who only knows how to generate code quickly with AI.
Each topic here deserves its own deep-dive article. In this article, I want to show the senior developer mindset behind each concept and share useful materials to learn from.
CRUD is the foundation of most backend systems. It can vary from a simple single-action endpoint to a large data aggregator with joins, filtering, pagination, and chunking.
A strong API needs clear resource design, proper authentication, permissions, pagination, filtering, sorting, and validation. It should follow consistent REST principles, return meaningful status codes, and handle edge cases in a predictable way.
Things a senior backend engineer should always think about when building or designing an API:
This is one of the most common areas where AI-generated code looks fine at first but breaks under real use. A good backend engineer knows how to make the API simple for the client and safe for the server.
Webhooks are one of the most common backend integrations in real projects. They allow external services to notify your system when something happens.
At first, building a webhook may seem easy. You create an endpoint, receive a payload, and update something in your system. But in real projects, webhooks have a lot of nuances.
I have personally built around 20–25 webhook handlers for different services, and one thing becomes clear very quickly: every provider does webhooks differently.
Some providers use HMAC signatures. Some use basic auth. Some send a unique event ID. Some do not. Some retry events for hours or days. Some send the full object in the payload, while others only send an ID and expect you to fetch the latest state from their API.
That is why the important skill is not just “how to create a webhook endpoint.” The important skill is how to design a standardized webhook receiver pattern inside your own system.
Race conditions are especially important. for example, two webhook events for the same payment, order, subscription, or delivery can arrive at almost the same time. If both handlers read the same database state and update it independently, you can process the same action twice or move the object into the wrong state. Database-level constraints are important, but they are not always enough. They can prevent invalid duplicate data, but they may still result in errors or failed processing if two handlers race with each other.
To reduce this risk, wrap critical webhook processing in a database transaction. For important objects such as payments, orders, subscriptions, or deliveries, use row-level locking with something like SELECT … FOR UPDATE.

But this is not a silver bullet, and your exact implementation may differ depending on the case.
Standard Webhooks is still a good reference. Not every provider follows it, but it gives a good mental model for how webhooks should work.
Senior level developer should also consider a safe webhook pattern that works across many different providers.
Almost every backend system eventually needs to talk to external APIs. Payments, email, messaging, analytics, document generation, storage, CRM, and AI services all depend on this.
External API work is not just calling requests.get() or httpx.post(). But in real projects, the API call itself is usually the easiest part.
I have worked with many external services, and one thing becomes clear very quickly: every provider has its own behavior. Different authentication methods, different status codes, different retry rules, different rate limits, different pagination styles, different SDK quality, and different edge cases.
That is why the important skill is not just “how to call an API.” The important skill is how to design a safe and maintainable integration layer inside your system.
A senior engineer should know when to use the SDK and when direct HTTP is better. SDKs can save time and reduce mistakes, but sometimes they hide too much behavior or make debugging harder. Raw HTTP can be better when you need full control.
The most important rule is that external dependency logic should not be spread across the whole codebase. If every view, task, or service calls the provider directly, the system becomes hard to test, hard to debug, and hard to replace later.
Good integration code should fail clearly, retry safely, respect provider limits, avoid duplicate side effects, and be easy to debug in production.
Excel and CSV import/export features often look simple at first. A user uploads a file, the system reads it, saves the data, and maybe later exports the same data back.
But in real projects, import/export features need much more care than people expect.
Users can upload files with missing values, wrong column names, duplicated rows, extra columns, bad formatting, invalid dates, inconsistent numbers, different encodings, or data that does not match your internal model. The UI may show only one upload button, but the backend needs to handle many edge cases.
That is why the important skill is not just “how to parse a CSV file.” The important skill is how to design a safe and predictable import/export pipeline.
Transactions are also important. If the import should be all-or-nothing, you can wrap the database changes in an atomic transaction. If one row fails, everything is rolled back.
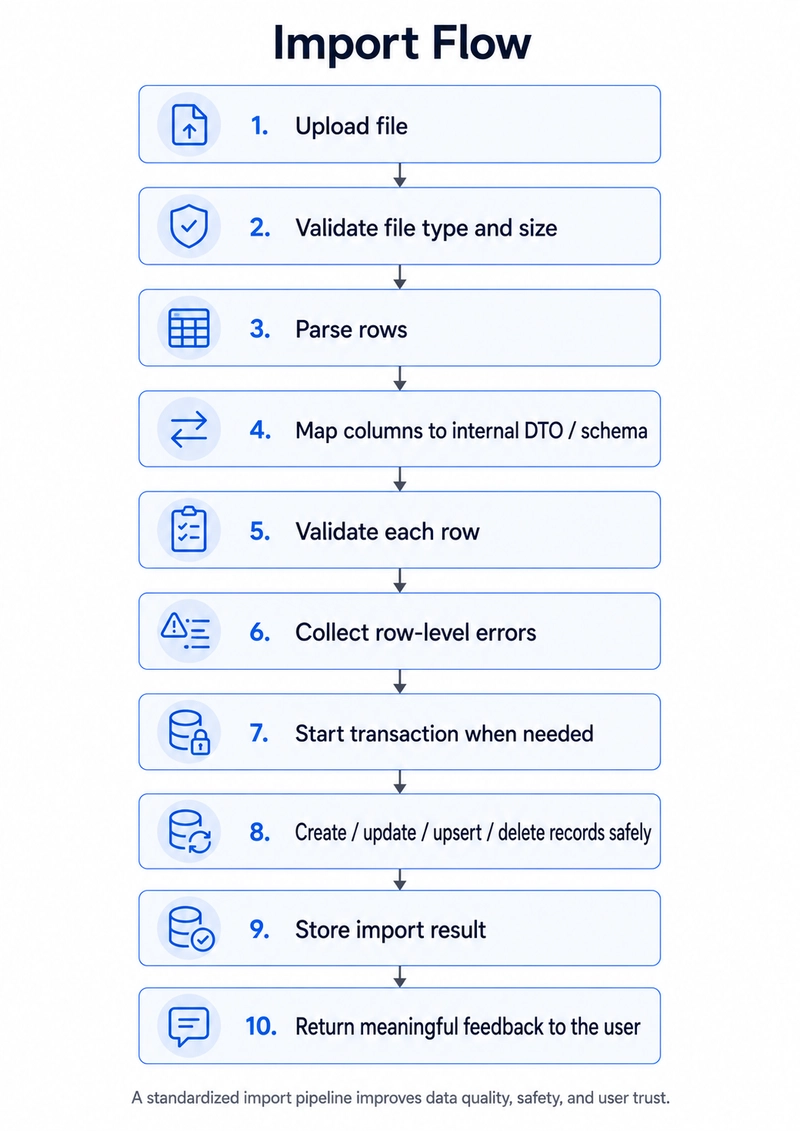
Idempotency matters too. If the same file is uploaded twice, the system should not create duplicate records accidentally. Depending on the business logic, you may need unique constraints, external IDs, upsert logic, or an import history table to detect repeated imports.
Export has the same kind of complexity in the other direction. You need to decide which fields to include, how to format dates and numbers, how to handle permissions, how to avoid exporting sensitive data, and whether the export should happen immediately or as a background job.
This is one of those backend features that looks straightforward in the UI, but becomes much more interesting once you start dealing with real data.
Background tasks are one of the most important parts of a backend system because not everything should happen inside the request-response cycle.
This includes things like sending emails, processing imports, generating reports, handling webhook events and offloading heavy or long-running tasks to dedicated workers. The main goal is to keep the user request fast while the real work happens safely in the background.
Once you introduce background jobs, queue reliability becomes a real concern. You need to think about retries, backoff, failure handling, idempotency, worker crashes, and what happens when a task runs more than once. A task system is only useful if you can trust it under load and when things fail.
One of the biggest mistakes is assuming that a task will always run exactly once. In production, this is not always true. A worker can crash. The broker connection can be interrupted. A task can be redelivered. A retry can happen after a partial update. Two identical tasks can be triggered at almost the same time.
That is why background task logic should usually be designed as at-least-once execution, not exactly-once execution. Your task may run more than once, so your code should be safe when that happens.
for example, a task that sends an email, updates a subscription, processes a payment, or syncs data from an external API should check the current state before applying changes. Depending on the case, you may need idempotency keys, unique constraints, deduplication locks, row-level locks, or status fields to prevent duplicated side effects.
I have a separate article about using Celery with Redis in production, where I go deeper into these settings and the real problems they solve.
Are you sure you want to hide this comment? It will become hidden in your post, but will still be visible via the comment’s permalink.
For further actions, you may consider blocking this person and/or reporting abuse
DEV Community — A space to discuss and keep up software development and manage your software career
Built on Forem — the open source software that powers DEV and other inclusive communities.
Why it matters
News like this often changes audience expectations and competitors’ plans.
When one player makes a move, others usually react — it is worth reading the event in context.
What to look out for next
The full picture will become clear in time, but the headline already shows the dynamics of the industry.
Further statements and user reactions will add to the story.