The topic of I automated my news discovery with one tool, and now I spend half the time finding… is currently the subject of lively debate — readers and analysts are keeping a close eye on developments.
This is taking place in a dynamic environment: companies’ decisions and competitors’ reactions can quickly change the picture.
As a journalist, I’ve spent a lot of time refining and reworking my workflow. Discovering news and keeping up with it is just as important to me and my job as reporting and writing. For my morning routine, I have a mental list of websites to check and keep tabs on. And while the system works, it’s far from ideal. Every morning I open the same set of tabs, check author pages, skim through product and open-source blogs, check changelogs, and hope that I haven’t missed out on something important. It’s a productive start to the day, but it is far from efficient. In fact, it’s a slow, repetitive process that depends too much on me remembering what to check. Elsewhere, there are RSS readers, but as it turns out, in 2026, way too many websites have either poor or no RSS support at all.
The news sources I care about are spread across a wide variety of websites, and when I’m particularly interested in posts from specific authors, the lack of an RSS feed really hurts. The constant manual browsing and searching was exactly what I wanted to avoid. That’s what pushed me towards the interesting open-source app I recently discovered, HTML2RSS. I wanted to build a fairly automated system where updates came to me instead of me seeking them out. And this tool has helped me change the way I discover information every day. Here’s why.
Self-hosting FreshRSS gives you speed, privacy, and customization in one package
You might think the biggest issue I faced was that not every website offers a proper RSS feed. While that’s true, it’s only part of the issue. The larger problem is that most websites want to keep you within the ecosystem. I’m not going to go on a tirade about diminishing media revenues, but for better or worse, websites want you on the homepage, clicking through related stories and recommendations, which is precisely why RSS is going the way of the dodo. I wanted to do the exact opposite of that. I wanted a clean stream of story updates, free of distractions.
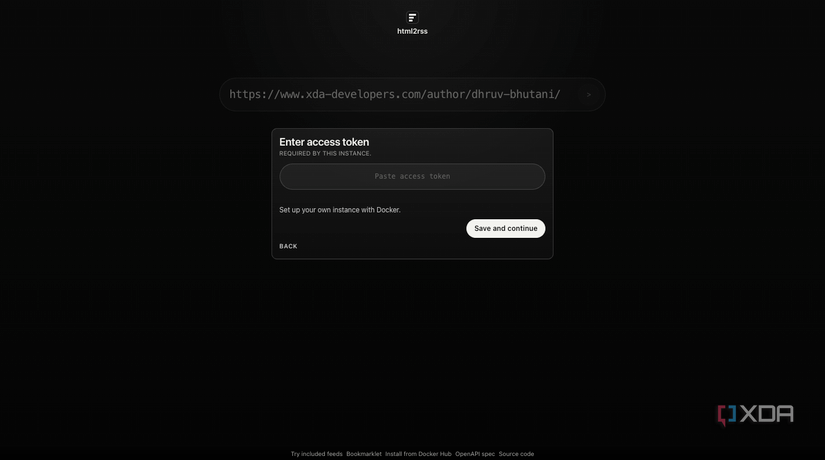
HTML2RSS helps you achieve precisely that by creating RSS feeds directly from web pages, rather than depending on whether the site provides one. Under the hood, the tool runs a scraper that starts with a simple request and falls back to browser automation to access the webpage in question. The installation is fairly standard via Docker, and you can use the provided quick-start Docker Compose file to get started.
Since simple scraping doesn’t always work, HTML2RSS includes a couple of fallback options to ensure your requested feed is downloaded. This includes Botasaurus and yet another fallback to Browserless. The entire service is built around reliability, and it’s been pretty fail-safe in my testing so far.
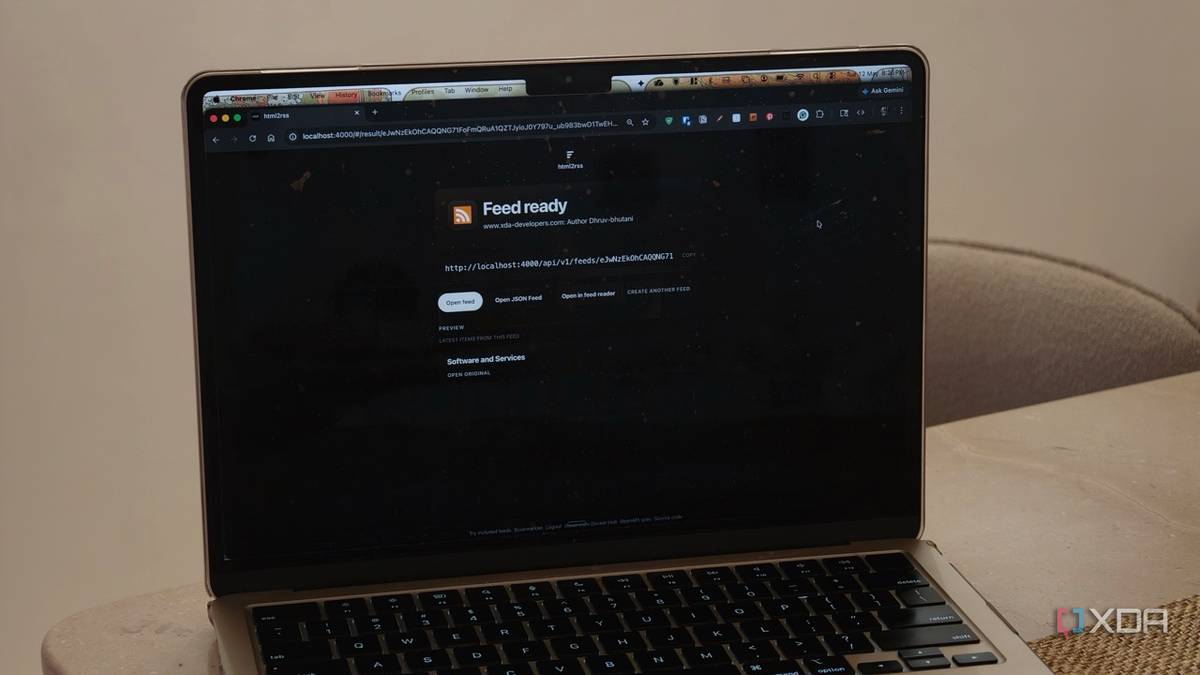
As I mentioned earlier, my goal was to download author feeds, including my own, for archival purposes, but many websites don’t offer that as a feature. Including XDA, for that matter. HTML2RSS lets you enter a URL and generate a custom RSS feed automatically. Just paste the URL, and the tool automatically detects the structure and gives you a feed. There are configuration options available if the extraction isn’t quite right, but I’d say more often than not, it gets it right. Just take the generated feed, pop it into an RSS reader, and your curation begins.
A lot of self-hosted tools expect you to put in a serious amount of effort to get the results you’re looking for. As an amateur developer at best, these tools often go over my head. I like that segregation here. There’s a clear, simple workflow to get you started, with a quickstart deployment included. Just verify if the feed generation worked, and you’re good to go. You’ll even find a built-in feed directory. That quickstart configuration saved me from having to manually write selectors and figure out extraction rules, which would have absolutely nosedived my progress.
So, how well did it fit into my workflow? Astonishingly well, to the point that it’s become a key part of my daily research process. While HTML2RSS on its own isn’t going to replace all your existing sources, it doesn’t really need to. I’ve got a copy of FreshRSS on my home server that pulls in all my existing news feeds. After generating news feeds for all the sources I manually checked every morning, I now have a single home for all the news I need. That flexibility is what makes HTML2RSS so useful for me. Call me old school, but I like to sift through my news manually and on my own terms instead of an LLM deciding for me what I should read. But that’s a conversation for another day.
A couple of days into HTML2RSS, my biggest takeaway wasn’t that I had fewer feeds; in fact, I had more. But I had fewer distractions. Usually, when you’re browsing manually, it is easy to get distracted by sidequests. But by pulling all the key authors, writers, and news sources into the same triage spot where all my other news sources live, I have a more focused and intentional approach towards news discovery, and it’s already showing up in how much time I’m saving. If you are an avid newshound, I’d highly recommend checking out this self-hosted tool.
HTML2RSS is an open-source tool that can turn any webpage into functional RSS feed even if the website does not offer native support.
Why it matters
News like this often changes audience expectations and competitors’ plans.
When one player makes a move, others usually react — it is worth reading the event in context.
What to look out for next
The full picture will become clear in time, but the headline already shows the dynamics of the industry.
Further statements and user reactions will add to the story.