The topic of PACELC Theorem in System Design is currently the subject of lively debate — readers and analysts are keeping a close eye on developments.
This is taking place in a dynamic environment: companies’ decisions and competitors’ reactions can quickly change the picture.
The PACELC Theorem represents a foundational advancement in understanding the inherent trade-offs that define modern distributed systems. Developed as a direct extension of the CAP Theorem, it provides architects and engineers with a more complete framework for reasoning about system behavior under both failure conditions and normal operations. Where earlier models focused narrowly on rare network failures, the PACELC Theorem acknowledges that consistency, availability, and latency constantly interact in real production environments.
The CAP Theorem established that in the presence of a network partition, a distributed system can guarantee only two out of three properties: Consistency, Availability, and Partition Tolerance. This insight proved invaluable for designing fault-tolerant architectures. However, it left a critical gap unaddressed. The CAP Theorem offered no guidance on system behavior during the vast majority of time when no network partition exists. In practice, distributed databases and microservices spend most of their operational life in a healthy state, yet they still face unavoidable trade-offs.
The PACELC Theorem, proposed by Daniel Abadi, bridges this exact limitation. It formalizes the reality that even without failures, designers must choose between latency and consistency. The theorem therefore expands the conversation from failure-only scenarios to the continuous operational reality of distributed systems.
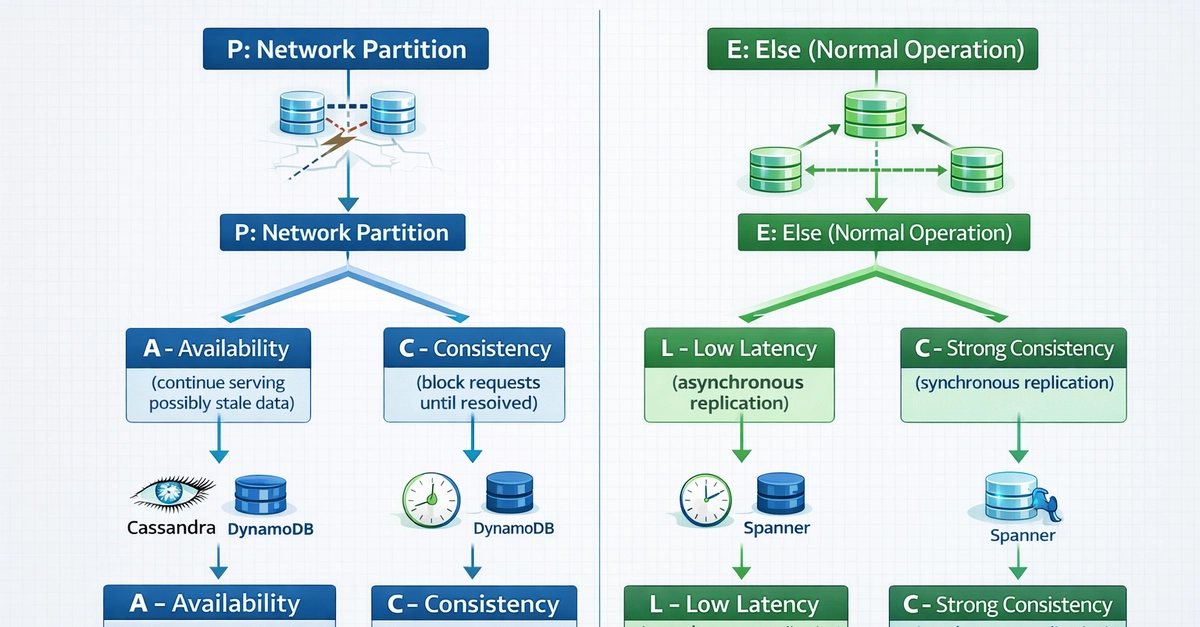
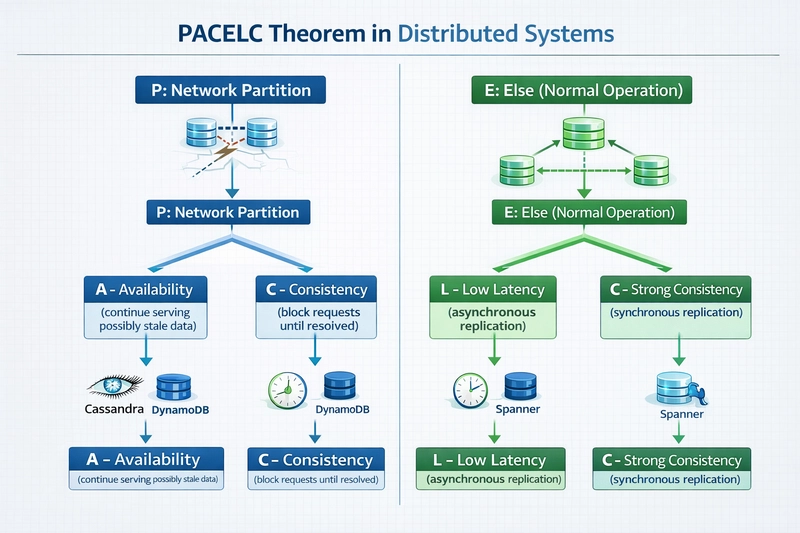
The PACELC Theorem breaks down into two distinct decision points that every replicated distributed system must navigate.
P stands for Partition. When a network partition occurs, nodes or groups of nodes become unable to communicate. At this moment the system must decide between A (Availability) and C (Consistency).
A represents Availability: the guarantee that every request receives a non-error response, even if the response reflects stale data.
C represents Consistency: the guarantee that all nodes return the most recent successful write, ensuring linearizability across the system.
E stands for Else. This clause addresses the normal operating state when no network partition is present and the cluster functions with full connectivity.
In the Else case, the system must still choose between L (Latency) and C (Consistency).
L represents Latency: the time taken to complete read or write operations. Lower latency improves user experience and throughput but often requires relaxing guarantees about data freshness.
C again represents Consistency, now enforced through synchronous coordination that inevitably increases response times.
The complete formulation therefore states: in the case of a network partition (P), a distributed system can trade off availability (A) and consistency (C); else (E), when the system operates normally, it must trade off latency (L) and consistency (C).
During a network partition, the system faces an existential choice. Prioritizing Availability means continuing to serve requests from whichever partition can respond. Some nodes may return stale data, but the service remains usable. Prioritizing Consistency means refusing requests that cannot be verified against the latest state, potentially rendering parts of the system unavailable until the partition heals.
This decision directly maps to the CAP Theorem but gains precision when combined with the Else clause. Real systems rarely stay partitioned indefinitely, so the PACELC Theorem forces designers to consider both the failure mode and the recovery behavior.
The true power of the PACELC Theorem emerges in the Else case. Even with perfect connectivity, synchronous replication across multiple nodes introduces latency. A write must reach a quorum or all replicas before acknowledgment, increasing response time. Asynchronous replication reduces latency dramatically but risks temporary inconsistency until replication catches up.
This latency versus consistency trade-off occurs constantly. High-traffic applications serving millions of users per second cannot afford the overhead of strong consistency on every operation. Conversely, financial or inventory systems cannot tolerate even brief windows of stale data.
Distributed systems fall into four primary categories based on their PACELC choices:
Apache Cassandra operates as a classic PA/EL system. It uses a tunable consistency model allowing developers to choose consistency levels per query, but defaults to behaviors that favor Availability and low latency. During a partition, Cassandra continues serving requests from available nodes. Under normal conditions, writes return quickly after reaching a single node or local quorum, with background repair mechanisms ensuring eventual consistency.
Amazon DynamoDB follows the same PA/EL pattern. It delivers single-digit millisecond responses at global scale by defaulting to eventual consistency. Developers can request strongly consistent reads when needed, but this option explicitly increases latency and reduces Availability under certain failure modes, demonstrating the PACELC trade-off in action.
MongoDB typically behaves as a PA/EC system. It can maintain Availability during partitions while guaranteeing Consistency for reads and writes under normal operation through primary-secondary replication and careful write concern settings.
Google Spanner and HBase exemplify PC/EC systems. They refuse to compromise Consistency even during partitions, using sophisticated consensus protocols like Paxos or Raft. Writes may block or fail until quorum agreement, and reads always reflect the latest committed state. The resulting higher latency and occasional unavailability represent the deliberate cost of absolute Consistency.
To illustrate these concepts concretely, consider the following complete examples that demonstrate PACELC trade-offs in practice.
The following CQL statements show how Cassandra exposes the latency-consistency choice directly to the application layer:
In the ONE consistency level, the operation completes after a single replica acknowledges the write or read, delivering minimal latency at the cost of possible temporary inconsistency. The QUORUM level requires majority acknowledgment, enforcing stronger Consistency while increasing latency and reducing effective Availability during partial failures.
The following complete Python implementation demonstrates a simplified replicated key-value store that lets the developer choose between low-latency asynchronous replication and high-consistency synchronous replication:
This simulation makes the PACELC trade-off explicit. The write_elastic method returns almost instantly while background threads handle replication, embodying PA/EL behavior. The write_strong method blocks until every replica acknowledges, providing PC/EC guarantees at the measurable cost of increased latency.
When architecting new distributed systems, evaluate requirements against both branches of the PACELC Theorem. High-throughput applications such as social feeds, recommendation engines, or IoT telemetry streams benefit from PA/EL designs. Mission-critical systems handling financial transactions, inventory management, or medical records demand PC/EC approaches despite the performance penalty.
Hybrid strategies also exist. Many production systems implement dynamic consistency tuning based on context. A single API endpoint may offer both eventual and strong read paths, allowing clients to select the appropriate latency-consistency balance per request.
The PACELC Theorem ultimately equips system designers with the vocabulary and mental model necessary to make intentional, evidence-based decisions rather than defaulting to marketing claims or oversimplified diagrams.
system Design Handbook
If you found this deep dive valuable, grab the complete system Design Handbook packed with 40+ essential concepts, real architectures, and production-grade examples: https://codewithdhanian.gumroad.com/l/ntmcf
Buy me coffee to support my content at: https://ko-fi.com/codewithdhanian
Are you sure you want to hide this comment? It will become hidden in your post, but will still be visible via the comment’s permalink.
For further actions, you may consider blocking this person and/or reporting abuse
DEV Community — A space to discuss and keep up software development and manage your software career
Built on Forem — the open source software that powers DEV and other inclusive communities.
Why it matters
News like this often changes audience expectations and competitors’ plans.
When one player makes a move, others usually react — it is worth reading the event in context.
What to look out for next
The full picture will become clear in time, but the headline already shows the dynamics of the industry.
Further statements and user reactions will add to the story.