
The topic of Resume tokens and last-event IDs for LLM streaming: How they work & what they… is currently the subject of lively debate — readers and analysts are keeping a close eye on developments.
This is taking place in a dynamic environment: companies’ decisions and competitors’ reactions can quickly change the picture.
When an AI response reaches token 150 and the connection drops, most implementations have one answer: start over. The user re-prompts, you pay for the same tokens twice, and the experience breaks.
Resume tokens and last-event IDs are the mechanism that prevents this. They make streams addressable – every message gets an identifier, clients track their position, and reconnections pick up from exactly where they left off. The concept is straightforward. The production scope is not: storage design, deduplication, gap detection, distributed routing, and multi-device continuity all follow from the same first decision.
Message identifiers. Every token or message gets a sequential ID when published – monotonically increasing, so each new message has a higher ID than the previous one.
Client state. The client tracks the ID of the last message it successfully received. In a browser, that’s typically held in memory or local storage. On mobile, it needs to survive app backgrounding.
Reconnection protocol. When the connection drops, the client presents the last ID it saw. The server responds with everything that arrived after that ID, then transitions to live streaming.
Catchup delivery. The client receives missed messages in order before live tokens resume. The seam should be invisible.
The stream itself becomes the source of truth. The client doesn’t reconstruct what it missed – the stream delivers it.
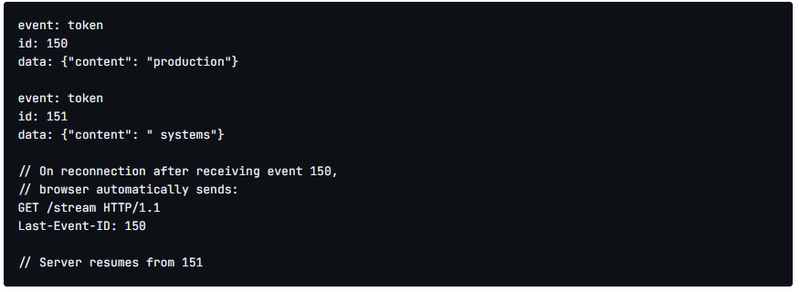
Server-Sent Events implements this natively. When an SSE connection drops, the browser automatically includes a Last-Event-ID header on reconnection. The server sees which event the client last received and resumes from there.
The browser handles reconnect logic. Application code doesn’t change between initial connection and reconnection. For the happy path – stable connection, single device, short responses – SSE with Last-Event-ID works well.
SSE is unidirectional and HTTP-only. It has no native history beyond what you implement server-side. It doesn’t handle bidirectional messaging, so live steering – users redirecting the AI mid-response – requires a separate channel. On distributed infrastructure, a reconnecting client may reach a different server instance that has no record of the original session. SSE handles the reconnect handshake. Everything else – distributed state, per-instance routing, multi-device history – is still your problem. For use cases that need bidirectional messaging, WebSockets vs SSE covers the tradeoffs in detail.
WebSockets don’t include resume semantics. When a WebSocket closes, the connection is gone. Reconnecting creates a new socket with no knowledge of the previous one.
Session IDs generated at stream start, stored server-side, presented by the client on reconnection. Message IDs assigned sequentially. Server logic to look up a session, find the position, replay history, then transition to live. Buffer management to decide how long to keep messages for sessions that haven’t reconnected yet. Cleanup logic to expire stale sessions without cutting off legitimate reconnects.
Each piece is straightforward in isolation. The edge cases are where the weeks go.
A 500-word response generates roughly 625 tokens. If you store each token as a separate record, loading one response means retrieving 625 records. A conversation with 20 exchanges is 12,500 records. Multiply across thousands of concurrent users and history retrieval becomes the performance bottleneck.
This matters because history retrieval is on the critical path for multi-device continuity. When a user switches from laptop to phone, the speed of catchup determines whether the experience feels continuous or broken.

The more practical model is to treat each AI response as a single logical message and append tokens to it rather than publishing them individually. Clients joining mid-stream receive the full message so far, then get new tokens as they arrive. One record per response instead of hundreds.
Duplicates happen when the connection drops after the client receives a message but before the acknowledgement reaches the server. On reconnect, the server doesn’t know whether to replay that message. Without deduplication logic, the client renders the same token twice.
The fix is using message IDs as deduplication keys on the client – straightforward in principle, but it needs to survive page reloads and work across tabs.
Gaps happen when sequential IDs arrive out of order or not at all. If a client receives message 153 after 150, messages 151 and 152 are missing. Without gap detection, the client silently renders an incomplete response. With it, you need logic to request missing messages, decide what to do if they can’t be retrieved, and handle the state when the client gives up waiting.
Both failure modes are rare enough to be invisible in testing. Both surface under real network conditions: mobile handoffs, flaky WiFi, corporate proxy timeouts. The first time you see them is usually a support ticket.
A single-server implementation can tie session state to process memory and mostly work. As soon as you run multiple instances – which you will, for reliability and scale – a routing problem appears.
A client that connected to instance A reconnects to instance B. Instance B has no record of the session. Your options: route all reconnections back to the originating instance (a pinning strategy that creates hotspots and defeats the purpose of multiple instances), or store session state in shared infrastructure that all instances can read.
Shared session storage means Redis or equivalent: network round-trips on reconnect, cache invalidation logic, and failure handling when the cache is unavailable. This is solvable. It’s also not in the first implementation.
When state lives in the connection – or in server memory tied to that connection – device switching loses context. The phone doesn’t know what the laptop received. Without a shared source of truth for message history that any device can query, each reconnect from a new device is a new session.
This is a different architectural model than resuming an HTTP stream. For most teams, that realisation arrives after the first implementation is already in production.
Not every streaming application needs this. For short-lived, single-session interactions on stable connections, standard HTTP streaming is fine.
Mobile clients handle network handoffs between WiFi and cellular constantly. Each one is a potential disconnection.
Long responses – anything over 30 seconds – have a high probability of encountering a transient failure.
Multi-device usage means the conversation needs to live in a channel, not a connection.
Multi-agent systems, where several agents publish updates to a shared channel. A reconnecting client needs to catch up on everything all agents published, not just the primary response thread.
The alternative is forcing users to restart on every interruption. That breaks trust fast, and the cost compounds on longer or more complex tasks where restarting is most painful.
Teams that have shipped resumable streaming in production describe a consistent arc: the first implementation takes a week, the edge cases take a month, and cross-device reliability is still not fully solved six months later.
The full scope of a production-grade build: session management, message storage with efficient retrieval by ID range, client-side deduplication, gap detection, distributed routing, cache invalidation, buffer expiry, and monitoring to surface issues you can’t reproduce locally.
Good transport infrastructure handles duplicates and gaps automatically. Application logic shouldn’t need to check for either – that’s the infrastructure’s job.
Building resumable streaming yourself is a reasonable choice if you have a stable team, time to maintain it, and no multi-device or distributed requirements.
It’s a harder choice than the SSE documentation makes it look. One team described spending several weeks on custom session management and still not fully solving cross-device reliability. The problems weren’t obvious in the design phase – they appeared under mobile network conditions, under load, and when users did things the system wasn’t built to handle.
The alternative is transport infrastructure that implements resume as part of the platform. You keep control of your LLM, prompts, and application logic. Session continuity, offset management, ordered delivery, and multi-device state become infrastructure concerns rather than application concerns.
Both paths are defensible. The costs of building are real and most of them are invisible until the first deploy.
Streaming responses between AI agents and clients? Ably AI Transport includes resumable token streaming, automatic replay, and channel-based delivery with guaranteed ordering. Docs go deeper.
Are you sure you want to hide this comment? It will become hidden in your post, but will still be visible via the comment’s permalink.
For further actions, you may consider blocking this person and/or reporting abuse
DEV Community — A space to discuss and keep up software development and manage your software career
Built on Forem — the open source software that powers DEV and other inclusive communities.
Why it matters
News like this often changes audience expectations and competitors’ plans.
When one player makes a move, others usually react — it is worth reading the event in context.
What to look out for next
The full picture will become clear in time, but the headline already shows the dynamics of the industry.
Further statements and user reactions will add to the story.