
The topic of There Are Two Gaps. Agents Closed One. The Other Is Yours. is currently the subject of lively debate — readers and analysts are keeping a close eye on developments.
This is taking place in a dynamic environment: companies’ decisions and competitors’ reactions can quickly change the picture.
The agent generates 40 lines of code. You read the diff. You approve the change.
What just happened there? You didn’t write code. You didn’t design a flow. You didn’t even click through a UI. You judged. And that judgment, that single moment of evaluation, is the most important skill in software development right now.
Software development is shifting from execution to evaluation. Agents write. Humans judge.
In The Design of Everyday Things, Norman introduced two fundamental gaps that exist between a user and any system they interact with:
The Gulf of Execution is the gap between what a user wants to do and how they figure out how to do it. How do I trigger this action? Where is the button? What’s the right command?
The Gulf of Evaluation is the gap between what the system did and whether the user understands if it worked. Did that do what I expected? Is the system in the right state? Was that correct?
For decades, most of the hard work in UX and developer tooling has been about closing the Gulf of Execution. Better affordances. Clearer navigation. Autocomplete. Syntax highlighting. Documentation. All of it aimed at the same question: how do I do this?
When you describe what you want to an agent (“add input validation to this form”), the agent doesn’t make you figure out how to do it. It just does it. It navigates the codebase, writes the code, runs the linter, and presents you with a diff.
The Gulf of Execution shrank dramatically. It collapsed into a single interface: the prompt.
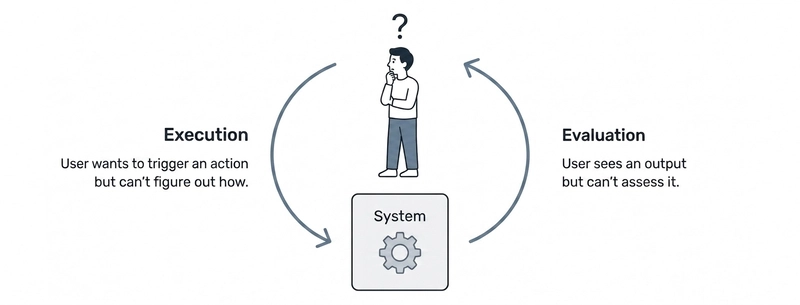
But it didn’t disappear. Prompting has its own Gulf of Execution. The same request that seems simple (“add input validation”) is actually ambiguous: client-side or server-side? Which library? What error messages? The user still has to know enough to instruct the system well. The Gulf of Execution compressed into prompting. The Gulf of Evaluation became the bottleneck.
Before agents, the vast majority of time went to execution. Evaluation happened naturally as a byproduct of doing. Now that execution is instant, the bottleneck shifts entirely to the evaluation side. The volume of output that needs review grows faster than the time available to review it. That’s not an incremental change. It’s a qualitative shift in what the job actually is.
That last question used to be trivial. Now it carries the entire weight of the interaction.
Human-in-the-loop (HITL) is not a new idea. It’s a well-established principle in ML systems: keep a human involved at some point in the automated decision cycle to ensure accuracy, safety, and accountability.
In the age of agentic tools, that question is already answered: yes, obviously. The human reviews the output before it ships. But that answer is no longer enough.
The answer depends on three variables: risk level, reversibility, and domain expertise required. Put together, they give you a practical heuristic:
In other words, deciding where the human sits in the loop is itself a Gulf of Evaluation problem. There’s no button that tells you if you got it right.
Cursor’s workflow makes this concrete. At every stage of the development cycle, someone decided who evaluates. That decision is design:
The human isn’t removed from the loop. They’re repositioned within it, and the position is a choice. Someone has to decide where the checkpoints are, what triggers human review, and what gets auto-approved. That’s not a technical decision. It’s a design decision with technical consequences.
The same pattern appears wherever agents generate output. In v0 or Google Stitch, a designer accepts or rejects a generated component. The loop is the same. The evaluation problem is the same. What varies is how explicit the checkpoints are and who owns them.
There’s a risk that comes with all of this: evaluation fatigue. When agents generate output faster than humans can meaningfully review it, the temptation is to approve without reading. The approval becomes automatic. That’s the failure mode this entire shift is trying to prevent. Designing the Gulf of Evaluation well means designing against that tendency, not just assuming that having a human in the loop is enough.
Agents can execute. They can verify. They can catch bugs, propose fixes, and review their own output. What they can’t do is develop judgment.
Judgment isn’t a skill you learn in a course. It’s built through years of shipping things that didn’t work, noticing what separates good from great, and developing an intuition for what’s right before you can articulate why. Taste works the same way. It accumulates slowly, through exposure to excellent work, through mistakes, through the friction of real constraints.
That’s not a temporary limitation of current models. It’s a structural difference between pattern recognition at scale and the kind of contextual understanding that comes from doing the work over time.
Are you sure you want to hide this comment? It will become hidden in your post, but will still be visible via the comment’s permalink.
For further actions, you may consider blocking this person and/or reporting abuse
DEV Community — A space to discuss and keep up software development and manage your software career
Built on Forem — the open source software that powers DEV and other inclusive communities.
Why it matters
News like this often changes audience expectations and competitors’ plans.
When one player makes a move, others usually react — it is worth reading the event in context.
What to look out for next
The full picture will become clear in time, but the headline already shows the dynamics of the industry.
Further statements and user reactions will add to the story.