The topic of Understanding Decoder-Only Transformers Part 1: Masked Self-Attention is currently the subject of lively debate — readers and analysts are keeping a close eye on developments.
This is taking place in a dynamic environment: companies’ decisions and competitors’ reactions can quickly change the picture.
Decoder-only transformers are a specific type of transformer architecture used in systems like ChatGPT.
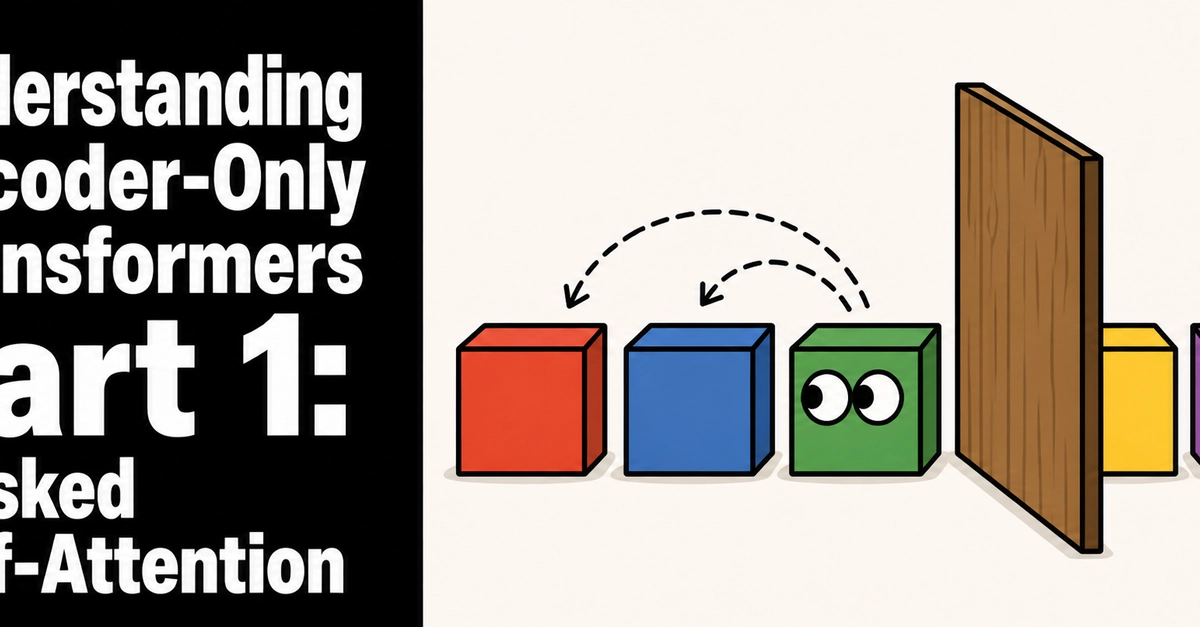
Masked self-attention works by measuring how similar each word is to itself and to the words that come before it in the sentence.
When processing the word “pizza”, masked self-attention only considers the preceding word “The”.

Unlike standard self-attention, masked self-attention does not allow a word to look at future words. It can only attend to the current word and the words that come before it.
An auto-regressive method is a way of predicting values step by step, where each prediction depends on the previous outputs.
Looking for an easier way to install tools, libraries, or entire repositories?
Try Installerpedia: a community-driven, structured installation platform that lets you install almost anything with minimal hassle and clear, reliable guidance.
Are you sure you want to hide this comment? It will become hidden in your post, but will still be visible via the comment’s permalink.
For further actions, you may consider blocking this person and/or reporting abuse
DEV Community — A space to discuss and keep up software development and manage your software career
Built on Forem — the open source software that powers DEV and other inclusive communities.
Why it matters
News like this often changes audience expectations and competitors’ plans.
When one player makes a move, others usually react — it is worth reading the event in context.
What to look out for next
The full picture will become clear in time, but the headline already shows the dynamics of the industry.
Further statements and user reactions will add to the story.